
네트워크 :: 네트워크?
HTTP 소개
HTTP란??
HyperText Transfer Protocol의 약자로 하이퍼 텍스트 문서를 교환하기 위하여 사용된 통신 규약이다. 즉, Web Server와 Web Client 간의 통신을 하기 위한 통신 규약이다. HTTP는 1989년 팀 버너스-리에 의해 처음 설계되어 인터넷을 통한 월드 와이드 웹(WWW)기반에서 전 세계적인 정보 공유를 이루는데 큰 역할을 하였다.
HTTP는 웹에서만 사용하는 프로토콜로 TCP/IP 기반으로 한 지점에서 다른 지점(서버와 클라이언트)으로 요청과 응답을 전송한다.
HTTP 특징
- HTTP 메시지는 HTTP 서버와 HTTP 클라이언트에 의해서 해석이 된다.
TCP/IP를 이용하는 응용 프로토콜- HTTP는 연결 상태를 유지하지 않는 비연결성 프로토콜 (이러한 단점을 해결하기 위해
Cookei와Seesing등장) - HTTP는 연결을 유지하지 않는 프로토콜이기 때문에
요청(request)/응답(response)방식으로 동작한다.
동작
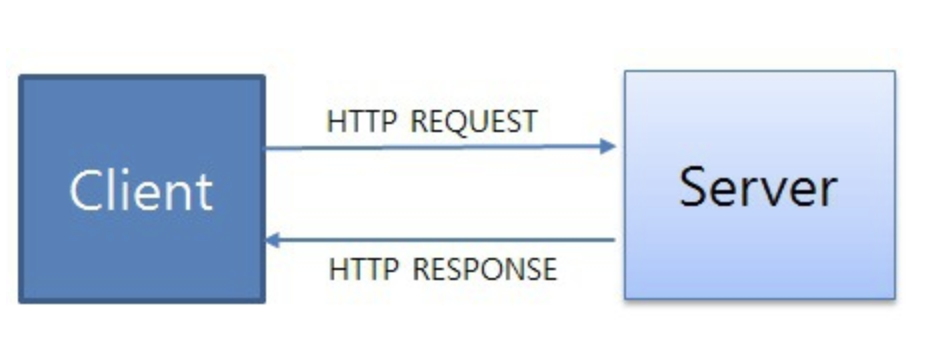
예를들면, 클라이언트(client) 즉, 사용자가 브라우저를 통해서 어떠한 서비스를 url을 통하거나 다른 것을 통해서 요청(request)을 하면 서버에서는 해당 요청사항에 맞는 결과를 찾아서 사용자에게 응답(response)하는 형태로 동작합니다
- 요청 : client -> server
- 응답 : server -> client
HTML 문서만이 HTTP 통신을 위한 유일한 정보 문서는 아니다 Plain text로부터 JSON 데이터 및 XML과 같은 형태의 정보도 주고 받을 수 있으며, 보통은 client가 어떤 정보를 HTML 형태로 받고 싶은지, JSON 형태로 받고 싶은지 명시해주는 경우가 많다.
HTTP의 GET과 POST 비교
둘 다 HTTP 프로토콜을 이용해서 서버에 무엇인가를 요청할 때 사용하는 방식이다. 하지만 둘의 특징을 제대로 이해하여 기술의 목적에 맞게 알맞은 용도에 사용할 수 있도록 알아보자.
GET
우선 GET 방식은 요청하는 데이터가 HTTP Request Message의 Header 부분의 url에 담겨서 전송된다. 때문에 url 상에 ? 뒤에 데이터가 붙어 request를 보내게 되는 것이다. 이러한 방식은 url이라는 공간에 담겨가기 때문에 전송할 수 있는 데이터의 크기가 제한적이다. 또 보안이 필요한 데이터에 대해서는 데이터가 그대로 노출되므로 GET 방식은 적절하지 한다.(ex. password)
POST
POST 방식의 request는 HTTP Message의 Body 부분에 데이터가 담겨서 전송된다. 때문에 바이너리 데이터를 요청하는 경우 POST 방식으로 보내야 하는 것처럼 데이터 크기가 GET 방식보다 크고 보안면에서 낫다. (하지만 보안적인 측면에서는 암호화를 하지 않는다면 고만고만하다…^^)
우선 GET은 가져오는 것이다. 서버에서 어떤 데이터를 가져와서 보여주는 용도이지 서버의 값이나 상태 등을 변경하지 않는다. SELECT적인 성향을 가지고 있다고 볼 수 있다. 반면에 POST는 서버의 값이나 상태를 변경하기 위해서 또는 추가하기 위해서 사용된다.
부수적인 차이점을 좀 더 살펴보면 GET 방식의 요청은 브라우제에서 Caching할 수 있다. 때문에 POST 방식으로 요청해야 할 것을 보내는 데이터의 크기가 작고 보안적인 문제가 없다는 이유로 GET 방식으로 요청한다면 기존에 Caching 되었던 데이터가 요청될 가능성이 존재한다. 때문에 목적에 맞는 기술을 사용해야 하는 것이다.
TCP 3-way-handshake & 4-way-handshake
- 연결 성립(Connection Establishment)
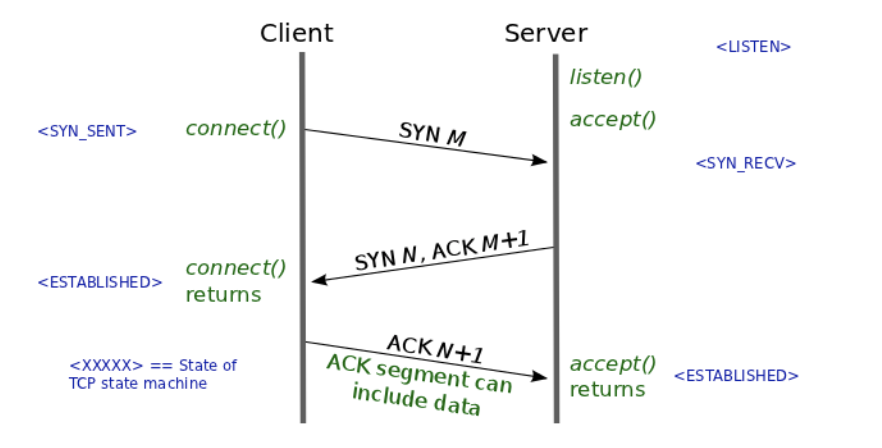
- client는 server에 접속을 요청하는
SYN(a)을 보낸다. - server는 client의 요청인
SYN(a)을 받고 client에게 요청을 수락한다는ACK(a+1)와SYN(b)이 설정된 패킷을 발송한다. - client는 server의 수락 응답인
ACK(a+1)와SYN(b)패킷을 받고ACK(b+1)를 server로 보내면 연결이 성립(establish)된다.
- 연결 해제(Connection Termination)
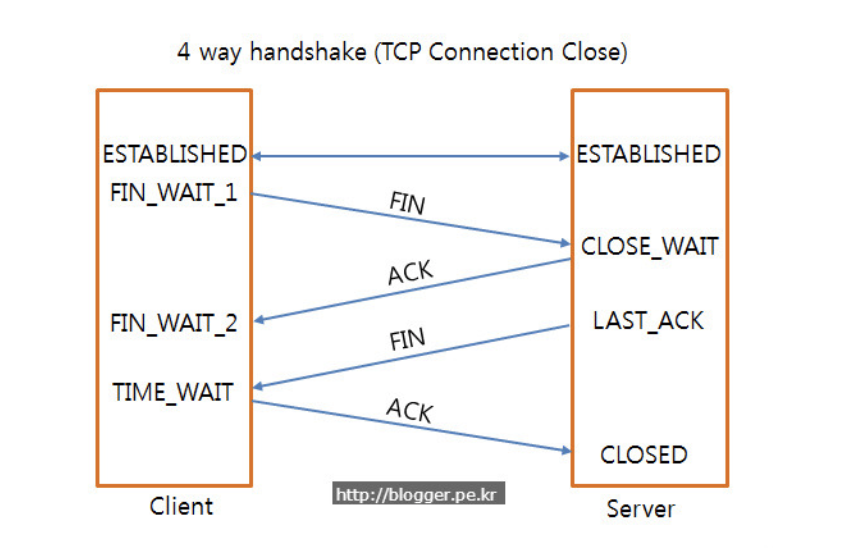
- client가 연결을 종료하겠다는 FIN 플래그를 전송한다.
- server는 client의 요청(FIN)을 받고 알겠다는 확인 메시지로 ACK를 보낸다.
2-1. 그리고 나서는 데이터를 모두 보낼 때까지 잠깐 TIME_OUT이 된다. - 데이터를 모두 보내고 통신이 끝났으면 연결이 종료되었다고 client에게 FIN 플래그를 전송한다.
- client는 FIN 메시지를 확인했다는 **메시지(ACK)**를 보낸다.
- client의 ACK 메시지를 받은 server는 소켓 연결을 close한다.
- client는 아직 server로부터 받지 못한 데이터가 있을 것을 대비해 일정 시간 동안 세션을 남겨놓고 잉여 패킷을 기다리는 과정을 거친다. (TIME_WAIT)
SYN : synchronize sequence number
ACK : acknowledgement
TCP header에는 Code Bit(Flag bit)라는 부분이 존재한다. 이 부분은 총 6bit로 이루어져 있으며 각각 한 bit들이 의미를 가지고 있다. Urg-Ack-Psh-Rst-Syn-Fin 순서로 되어 있으며 해당 위치의 비트가 1이면 해당 패킷이 어떠한 내용을 담고 있는 패킷이닞를 나타낸다. SYN 패킷일 경우에는 000010이 되고, ACK 패킷일 경우에는 010000이 되는 것이다.
Why tow types of packets?
일단 연결을 성립하려면 서로 통신이 가능한지를 먼저 파악하기 위해 패킷을 먼저 주고 받아야 한다는 것까지 이해가 되었다. 그런데 두 종류의 패킷을 주고 받는 다는 것은 요청과 응답에 대한 패킷을 주고 받아야 하기 때문에 두 종류인 것이다.
client가 자신의 목소리가 들리는지 물어본다.(SYN) server는 client의 목소리가 들린다고 말한다.(SYN+1) 그리고 자신(server)의 목소리가 들리는지 물어본다. (ACK) client는 server의 목소리가 들린다고 말한다. (ACK+1) 이런 과정인 셈이다. TCP Connection은 양방향성 connection이다. client에서 server의 존재를 알리고 패킷을 보낼 수 있다는 것을 알리듯, server에서도 client에게 존재를 알리고 패킷을 보낼 수 있다는 신호를 보내야 한다. 그렇기 때문에 2-way-handshake로는 부족하고 3-way-handshake를 사용해야 한다.
Why randomized sequence number?
처음 client에서 SYN 패킷을 보낼 때 Sequence Number에는 랜덤한 숫자가 담겨진다. 초기 sequence number ISN이라고 한다.
ISN이 0부터 시작하지 않고 난수를 생성해서 number를 설정하는 이유는 무엇일까???
그에 대한 해답은 여기서 확인할 수 있다.
Connection을 맺을 때 사용하는 포트(port)는 유한 범위 내에서 사용하고 시간이 지남에 따라 재사용된다. 따라서 두 통신 호스트가 과거에 사용된 포트 번호 쌍을 사용하는 가능성이 존재한다. server 측에서는 패킷의 SYN을 보고 패킷을 구분하게 되는데 난수가 아닌 순차적인 number가 전송된다면 이전의 connection으로부터 오는 패킷으로 인식할 수 있는 문제가 생긴다. 이러한 문제가 발생할 가능성을 줄이기 위해 난수로 ISN을 설정하는 것이다.
TCP vs UDP
인터넷은 Transport 계층에 연결형 프로토콜과 비연결형 프로토콜 두 개의 주된 프로토콜을 갖는다.
UDP
UDP(User Datagram Protocol)는 비연결형 프로토콜이다. IP 데이터그램을 캡슐화하여 보내는 방법과 연결 설정을 하지 않고 보내는 방법을 제공한다.
또한, UDP는 흐름제어, 오류제어 또는 손상된 세그먼트의 수신에 대한 재전송을 하지 않는다. 이 모두가 사용자 프로세스의 몫이다. UDP가 행하는 것은 포트들을 사용하여 IP 프로토콜에 인터페이스를 제공하는 것이다.
UDP가 특별히 유용한 분야는 Client-Server 상황이다. 종종 client는 server로 짧은 요청을 보내고, 짧은 응답을 기대한다. 만약 요청 또는 응답이 손실된다면, client는 time out 되고 다시 시도할 수 있다. 코드가 간단할 뿐만 아니라 TCP처럼 초기설정에서 요구되는 프로토콜에서보다 적은 메시지가 요구된다.
UDP를 사용한 것들에는 DNS가 있다. 어떤 호스트 네임의 IP 주소를 찾을 필요가 있는 프로그램은 DNS 서버로 호스트 네임을 포함한 UDP 패킷을 보낸다. 이 서버는 호스트의 IP 주소를 포함한 UDP 패킷으로 응답한다. 사전에 설정이 필요하지 않으며 그 후에 해제가 필요하지 않다.
UDP가 사용되는 또 다른 분야로는 실시간 멀티미디어가 있다. 실시간 멀티미디어의 응용이 많아지면서 오디오와 비디오 데이터 패킷 형식으로 전송하는 실시간 트랜스포트 프로토콜 (RTP : Real-time Transport Protocol)이 탄생했다. RTP의 기본 기능은 UDP 패킷의 단일 스트림으로 몇몇 실시간 데이터 스트림을 멀티플렉싱하는 것이다. UDP 스트림은 단일 목적지 또는 다중 목적지로 전송될 수 있다. RTP는 단지 일반적인 UDP를 사용하기 때문에 전달, 지연, 손실 등에 대한 특별한 보장이 없다.
이런 점들을 보완하기 위한 몇 가지 장치들이 존재한다. RTP 스트림에서 보내지는 각 패킷은 바로 전 패킷보다 하나 높은 번호가 주어진다. 이런 번호 부여 방식은 목적지로 하여금 어느 패킷이 분실되었는지 알 수 있게 한다. 만약 한 패킷이 없다면 이를 획득하기 위해 목적지에서의 최상의 동작은 보간(Interpolation)에 의해 손실한 값에 대한 근사치를 얻는 것이다. 재전송은 재전송된 패킷이 유용하기에 너무 늦게 도착하므로 실용적인 옵션이 아니다. 그러므로 RTP는 확인 응답이 없고 재전송을 요청하는 매커니즘도 없다.
TCP
대부분의 인터넷 응용분야들은
신뢰성과순차적인 전달을 필요로 한다. UDP로는 이를 만족시킬 수 없으므로 다른 프로토콜이 필요하여 탄생한 것이 TCP이다.
TCP(Transmission Control Protocol)는 신뢰성이 없는 인터넷을 통해 종단간에 신뢰성 있는 바이트 스트림을 전송하도록 특별히 설계되었다. TCP 서비스는 송신자와 수신자 모두가 소켓이라고 부르는 종단점을 생성함으로써 이루어진다. 각 소켓은 호스트의 IP 주소와 그 호스트에 국한된 16비트로 구성된 포트라고 불리는 소켓 번호를 갖는다. TCP 서비스를 하기 위해서는 송신측 소켓과 수신측 소켓이 연결되어 있어야 한다.
모든 TCP 연결은 전이중(full-duplex), 점대점(point to point) 방식이다.
전이중이란 전송이 양방향으로 동시에 일어날 수 있음을 의미하며 점대점이란 각 연결이 정확히 2개의 종단점을 가지고 있음을 의미한다. TCP는 멀티 캐스팅이나 브로드 캐스팅을 지원하지 않는다. 또한 메시지 스트림이 아니라 바이트 스트림의 형태를 갖는다. 메시지의 시작에서 끝까지의 경계가 유지되지 않는다.
TCP의 특징은 TCP 연결상의 모든 바이트가 고유의 32-비트 순서번호(sequence nunmber)를 갖는다는 것이다. 송수신 TCP 개체들은 세그먼트의 형태로서 데이터를 주고 받는다. 한 세그먼트는 고정 2바이트 헤더와 그 뒤를 따르는 0개 이상의 데이터 바이트들로 구성된다. TCP 소프트웨어는 세그먼트가 얼마나 커야 하는지를 결정한다. 세그먼트 크기에는 두 가지 제약요소가 있다. 한 가지는 모든 세그먼트들은 TCP 헤더를 포함하여 IP 수용량인 65,515바이트를 넘을 수 없다는 것이며 나머지 하나는 모든 네트워크는 정해진 MTU(Maximum transfer Unit, 최대 전송 단위)를 갖는데 각 세그먼트는 MTU를 넘을 수 없다는 것이다.
TCP 개체들에 의해 사용되는 기본 프로토콜은 동적으로 윈도우 크기를 조절하는 슬라이딩 윈도우(sliding window)프로토콜이다. 송신자는 한 세그먼트를 전송할 때, 타이머를 구동시킨다. 그 세그먼트가 목적지에 도달하면, 수신측 TCP 개체는 다음에 받으려고 하는 순서번호와 같은 확인 응답 번호를 포함하는 세그먼트를 송신측으로 보낸다. 보낼 데이터가 있다면 그 데이터와 함께 보낸다.
만일 확인 응답의 수신 전에 보낼 때 구동시킨 타이머가 종료되면 송신자는 그 세그먼트를 재전송한다. 세그먼트들이 순서가 뒤바뀐 상태로 도착할 수 있으며, 재전송 경우에 대해 올바르게 수신된 상태인지를 알 수 있도록 하는 장치가 필요하다. 스트림 내의 각 바이트가 자기 고유의 offset을 가지고 있는 것을 그 장치로 한다.
TCP에서 연결 설정(connection establishment)는 3-way-handshake를 통해 행해진다. 하나의 연결을 설정하려면 한쪽(서버)은 listen과 accept를 실행함으로써 연결 요청을 수동적으로 기다린다. 이 listen과 accept는 특정 근원지를 명시할 수도 있고 하지 않을 수도 있다. 다른 한쪽(client)은 connect를 실행하고 목적지 IP 주소와 포트, 수신 가능한 최대 TCP 세그먼트 크기 그리고 기타 사용자 데이터를 명시한다.
TCP에서 흐름제어는 가변 크기의 슬라이딩 윈도우를 사용하여 처리된다. window size 필드는 확인 응답된 바이트에서 시작하여 얼마나 많은 바이트가 보내질 수 있는지를 나타낸다. 그러나 이 경우 좋지 않은 상황이 발생할 수 있다. 송신자는 응용 프로그램에서 데이터가 올 때마다 전송할 필요가 없고 수신자도 마찬가지로 데이터를 받은 즉시 확인 응답을 해야 하는 것이 아니다. 버퍼를 사용하면 되기 때문에 데이터를 모아서 보내거나 그것을 받고 애플리케이션에서 모아서 전달할 수 있는 것이다.
각 키보드 입력마다 즉시 반응해야 하는 '인터렉티브 에디터(Interactive Editor)라면 어떨까??
송신측에서 한 번에 1 바이트씩 데이터를 전송해오는 것이다. 이러한 상황을 해결하기 위해 지연 확인 응답(delayed acknowledgement)방법을 사용한다. 응답 메시지를 전송하는 것과 윈도우 사이즈를 갱신하는 것을 지연시키는 것이다. 하지만 이 방법이 네트워크 부하를 감소시켜준다고 할 지라도 송신측에서는 계속해서 1바이트씩 보내게 된다.
그래서 네이글 알고리즘(Nagle Algorithm)을 통해 해결하곤 한다. 데이터가 한 번에 한 바이트씩 송신자에게 올 경우, 첫 번째 바이트만을 송신하고 나머지는 보낸 바이트에 대한 명백한 확인 응답이 올 때까지 버퍼에 보관한다는 것이다. 그리고 버퍼 내의 모든 문자를 하나의 TCP 세그먼트로서 전송한 후, 또 응답 메시지가 도착할 때까지 버퍼에 전송할 데이터를 저장한다. 하지만 이 알고리즘이 교착상태를 야기할 수 있고 그 결과 웹 페이지의 다운을 초래할 수 있다.
그런데 애플리케이션이 수신된 데이터를 1 바이트씩 가져간다면 어떻게 될까??
수신측은 버퍼에서 1 바이트가 비었기 때문에 window size를 1 바이트로 설정해서 응답을 하게 되고 송신측은 window size가 1 바이트니 1 바이트만큼의 데이터를 전송하게 된다. 1 바이트의 데이터를 보내기 위해서 41 바이트의 패킷 구성을 하는 비효율적인 상황이 발생하게 된다. 이런 상황을 silly window syndrome이라고 하는데, 이 상황을 최적화 하기 위해 1 바이트에 해당하는 윈도우 사이즈를 통보하지 않는다. 설정 당시 통보한 세그먼트의 최대 크기를 처리할 수 있게 되거나, 버퍼의 반이 빈 상태가 될 때까지 통보하지 않는 것이다. 송신자 측도 윈도우 사이즈가 커질 때까지 기다리는 것이다.