
[Data Structure] Tree 개념
Tree
트리는 스택이나 큐와 같은 선형 구조가 아닌 비선형 자료구조이다.
트리는 계층적 관계를 표현하는 자료구조이며, 표현에 집중한다.
무엇인가를 저장하고 꺼내야 한다는 사고를 벗어나 트리라는 자료구조를 보자.
트리를 구성하고 있는 구성요소들
- Node(노드) : 트리를 구성하고 있는 각각의 요소를 의미
- Edge(간선) : 트리를 구성하기 위해 노드와 노드를 연결하는 선을 의미
- Root Node(루트 노드) : 트리 구조에서 최상위에 있는 노드를 의미
- Terminal Node(=leaf Noed, 단말 노드) : 하위에 다른 노드가 연결되어 있지 않은 노드를 의미
- Internal Node(내부 노드, 비단말 노드) : 단말 노드를 제외한 모든 노드로 루트 노드를 포함한다.
트리의 속성 중 가장 중요한 것은 루트 노드를 제외한 모든 노드는 단 하나의 부모 노드만을 가진다는 것이다. 이 속성 때문에 트리는 다음의 성질을 만족한다.
- 임의의 노드에서 다른 노드로 가는 경로(path)는 유일하다.
- 회로(cycle)가 존재하지 않는다.
- 모든 노드는 서로 연결되어 있다.
- 엣지를 하나 자르면 트리가 두 개로 분리된다.
- 엣지의 수(E) = 노드의 수(V) - 1
Binary Tree(이진 트리)
루트 노드를 중심으로 두 개의 서브 트리(큰 트리에 속하는 작은 트리)로 나누어진다. 또한 나뉘어진 두 서브 트리 모두 이진 트리어야 한다.
즉, 각 노드가 자식을 최대 2명을 가지는 트리를 의미한다. 재귀적인 정의라 맞는듯 하면서도 이해가 쉽지 않다. 덧붙이자면 공집합도 이진 트리로 포함시켜야 한다. 그래야 재귀적으로 조건을 확인해갔을 때, leaf Node에 다 달았을 때 정의가 만족되기 때문이다.
트리에서는 각 층 별로 숫자를 매겨서 이를 트리의 Level이라고 한다. 루트 노드부터 시작하고 루트 노드의 Level은 1이다. 그리고 트리의 최고 Level을 가리켜 해당 트리의 height(높이)라고 한다.
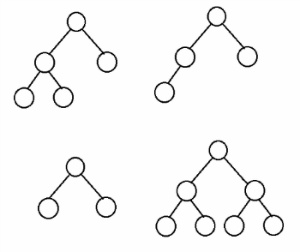
- 완전 이진 트리(Complete Binary Tree)
위에서 아래로, 왼쪽에서 오른쪽으로 순서대로 차곡차곡 채워진 이진 트리를 가리켜 완전 이진 트리라고 한다.
- 포화 이진 트리(Full Binary Tree)
모든 레벨에서 노드들이 꽉 채워진 이진트리를 말한다.(= 잎새 노드를 제외한 모든 노드가 자식 노드를 2개 가진다.)
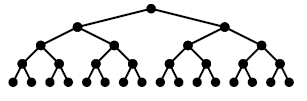
포화 이진 트리의 노드 수가 n개라면 잎새노드의 수는 n/2를 올림한 숫자가 된다. 그리고 노드의 개수는 2^(k+1) - 1이 된다.
- 편향 이진 트리(skewed binary tree)
모든 노드가 부모의 왼쪽 자식이기 때문에 왼편으로 편향되어 있거나 반대로 모든 노드가 부모의 오른쪽 자식으로 되어 오른쪽으로 편향되어 있는 이진트리를 말한다.
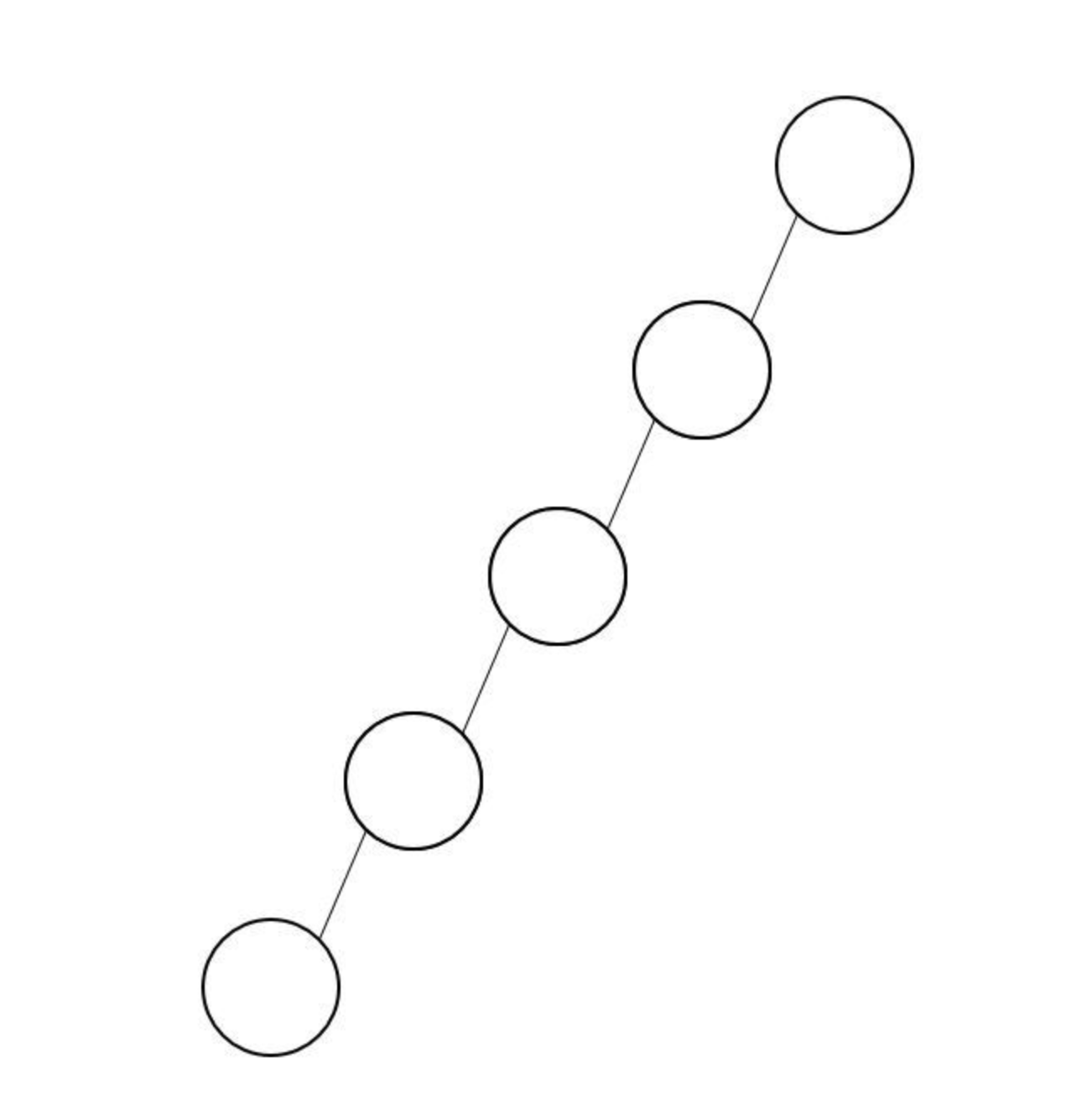
이러한 경우 사실 트리를 쓰는 이유가 사라지게 된다. 트리의 특정한 경우이지만 이렇게 된다면 탐색, 삽입, 삭제, 메모리 성능 등 모든 면에서 배열에 비해 좋은 것이 없다.
BST(Binary Search Tree)
효율적인 탐색을 위한 저장 방법이 무엇일까를 고민해야 한다.
이진 탐색 트리는 이진 트리의 일종이다.
단, 이진 탐색 트리에는 데이터를 저장하는 규칙이 있다.
그리고 그 규칙은 특정 데이터의 위치를 찾는데 사용할 수 있다.
- 규칙1 : 이진 탐색 트리의 노드에 저장된 키는 유일하다.
- 규칙2 : 루트 노드의 키가 왼쪽 서브트리를 구성하는 어떤 노드의 키보다 크다.
- 규칙3 : 루트 노드의 키가 오른쪽 서브트리를 구성하는 어떤 노드의 키보다 작다.
- 규칙4 : 왼쪽과 오른쪽 서브트리도 이진 탐색 트리이다.
이진 탐색 트리의 탐색 연산은 O(log n)의 시간 복잡도를 갖는다.
사실 정확히 말하면 O(h)라고 표현하는 것이 맞다. 트리의 높이를 하나씩 더해갈수록 추가할 수 있는 노드의 수가 두배씩 증가하기 때문이다.
이러한 이진 탐색 트리는 편항 트리가 될 수 있다. 저장 순서에 따라 계속 한 쪽으로만 노드가 추가되는 경우가 발생할 수 있기 때문이다.
이럴 경우 성능에 영향을 미치게 되며, 탐색의 Worst cost가 발생하고 시간 복잡도는 O(n)이 된다.
배열보다 많은 메모리를 사용하여 데이터를 저장했지만 탐색에 필요한 시간 복잡도가 같게 되는 비효율적인 상황이 발생했다.
이를 해결하기 위해 Rebalancing 기법이 등장했다.
균형을 잡기 위한 트리 구조의 재조정을 Rebalancing이라고 한다. 이 기법을 구현한 트리에는 여러 종류가 존재하는데 그 중에서 하나는 추후에 살펴볼 Red-black-Tree 이다.
이진 트리의 순회 방법
이진 트리의 순회 방법을 간단하게 정리하면 아래와 같다. 루트의 위치를 기준으로 이름을 기억하면 된다.
- 전위 순회(Preorder) : 루트 -> 왼쪽 서브트리 -> 오른쪽 서브트리
- 중위 순회(Inorder) : 왼쪽 서브트리 -> 루트 -> 오른쪽 서브트리
- 후위 순회(Postorder) : 왼쪽 서브트리 -> 오른쪽 서브트리 -> 루트