
[Java] 트라이(Trie) 자료구조 구현
구현 과정에서 람다를 사용하므로 Java 8을 베이스로 진행한다.
자바에서 Trie 구현하기
클래스 생성
자바로 Trie 자료구조를 구현하기 위해서는 자료구조인 Trie와 이를 구성할 TrieNode 클래스가 각각 필요하다.
먼저, TrieNode 클래스부터 보도록 하자.
TrieNode.java
- TrieNode는
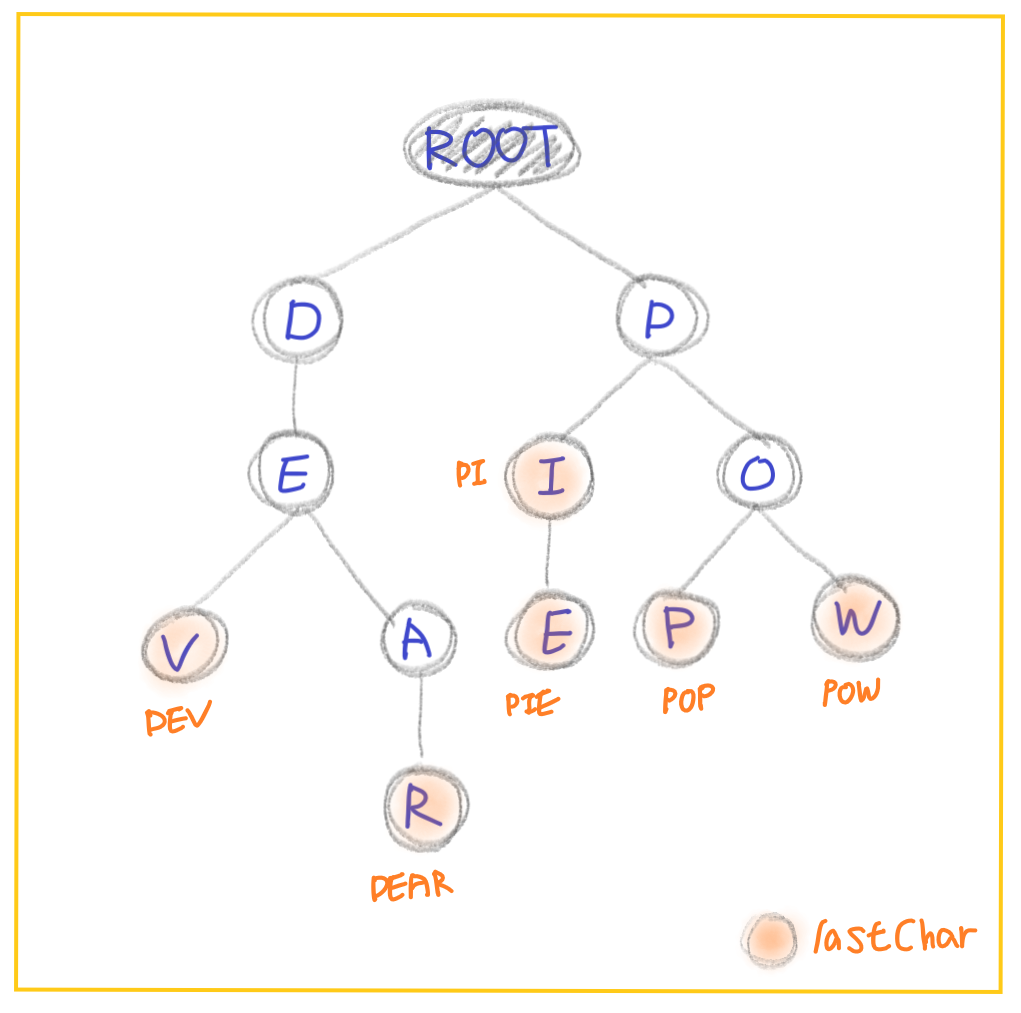
자식 노드맵과현재 노드가 마지막 글자인지 여부에 대한 정보를 가지고 있다. - 여기에서 마지막 글자 여부란 'DEV’라는 단어에서 [D], [E]는 마지막 글자가 아니지만 [V]는 마지막 글자로, 한 단어가 완성되는 시점임을 알 수 있도록 하는 boolean 값이다.
1 | import java.util.HashMap; |
- 이렇게 두 변수가 할당되었으면 이 변수에 접근할 수 있는 getter/setter를 구현한다. 자식 노드는 Trie 차원에서 생성해서 넣을 것이기 때문에 getter만 생성해준다.
- 마지막 글자 여부는 추후 노드 삭제하는 과정에서 변경이 필요하기 때문에 getter/setter를 둘 다 생성해준다.
1 | import java.util.HashMap; |
Trie.java
- Trie는
기본적으로 빈 문자열을 가지는 루트 노드만 가지고 있다. - 이후에 나올 insert() 메소드를 통해 단어를 넣음으로써 그에 맞게 자식 노드가 생성된다.
- 우선, Trie가 생성되면 rootNode가 생성될 수 있도록
생성자를 통해 rootNode를 초기화해준다.
1 | /** |
메소드 구현
- 이제 본격적으로 Trie 자료구조에 단어 정보를 저장(insert)하고, 해당 단어가 존재하는지 확인(contains)하고, Trie에서 특정 단어를 삭제(delete)하는 세 가지 메소드를 만들어보자.
1. insert
- 입력받은 단어의 각 알파벳을 계층 구조의 자식 노드로 만들어 넣는다.
- 이떄, 이미 같은 알파벳이 존재하면 공통 접두어 부분까지는 생성하지 않는다.
- 즉,
해당 계층 문자의 자식노드가 존재하지 않을 때에만 자식 노드를 생성해준다.(여기서 람다식 사용) - 예를 들면, 이미 'DEV’가 들어있는 Trie에 'DEAR’를 넣을 때, 'DE-'는 중복이므로 ‘D-E-’ 노드 아래 'A-R’만 추가로 자식 노드를 생성해주는 것이다.
- 그리고 마지막 글자에서는
여기까지를 끝으로 하는 단어가 존재한다는 표시를 위해 setLastCahr(true)해준다.
1 | // 자식 노드 추가. |
2. contains
- 특정 단어가 Trie에 존재하는지를 확인하기 위해서는 다음 두 가지 조건을 만족시켜야 한다.
- 루트 노드부터
순서대로 알파벳이 일치하는 자식 노드들이 존재할것! - 해당 단어의
마지막 글자에 해당하는 노드의 isLastChar가 true일 것!
(해당 글자를 마지막으로 하는 단어가 있다는 뜻)
- 루트 노드부터
- 여기서 두 번째 조건에 유념해야 한다.
- 예를 들어, Trie에는 'POW’와 'PIE’라는 단어만 등록되어 있는데, 'PI’라는 단어를 검색한다고 가정해보자.
- 'PI’는 'PIE’와 'PI-'가 일치하기 때문에 1번 조건에는 부합(PI가 PIE에 포함되는 단어)하지만, insert 메소드에서 'PIE’의 '-E’에만 setIsLastChar(true) 했기 때문에 2번 조건에는 부합하지 않아 Trie에 없는 단어임을 확인할 수 있게 된다.
1 | // 특정 단어가 들어있는지 확인. |
3. delete
-
마지막으로 Trie에 넣었던 단어를 삭제하는 과정이다.
-
contains 메소드처럼 주어진 단어를 찾아 하위 노드로 단어 길이만큼 내려간다.
-
주의할 점은 노드들이 부모노드의 정보를 가지고 있지 않기 때문에,
하위 노드로 내려가며 삭제 대상 단어를 탐색하고다시 올라오며 삭제하는 과정이 콜백(Callback) 형식으로 구현되어야 한다는 점이다. -
탐색 진행방향 : 부모 노드 -> 자식 노드
-
삭제 진행방향 : 자식 노드 -> 부모 노드
- 삭제 진행은 마지막 글자에서 부모 노드 방향으로 되돌아 오는 과정에서 진행된다는 점에 유이하여 다음 삭제 조건을 살펴보자.
- 자식 노드를 가지고 있지 않아야 한다.
위 그림에서 'PI’를 지워버리면 'PIE’까지 삭제되어 버리기 때문이다. - 삭제를 시작하는 첫 노드는 isLastChar == true이어야 한다.
false인 경우는 Trie에 없는 단어란 뜻이기 때문이다. 예를 들어, 위 그림에서 'PO’라는 글자를 지우라고 명령을 내려도 Trie가 가지고 있지 않은 단어라는 점이다. - 삭제를 진행하던 중에는 isLastChar == false이어야 한다.
삭제 과정 중에서 isLastChar가 true라는 것은 또다른 단어가 있다는 의미이므로 삭제 대상이 아니다. 'PIE’를 삭제 대상으로 했을 때, '-E’를 삭제 후 'PI’라는 단어의 'I’가 isLastChar==true이므로 또다른 단어가 있음을 알려준다.
- 자식 노드를 가지고 있지 않아야 한다.
3번이 의미하는 바는 이해가 잘 안갔지만, 이해가 되었다. 삭제 과정 중에 isLastChar가 true라는 것은 또 다른 단어가 있다는 의미이므로 삭제 대상이 아니다. 'PIE’를 삭제 대상으로 했을 때, '-E’를 삭제 후, 'PI’라는 단어의 'I’가 isLastChar == true이면 'PI’라는 단어가 있음을 뜻한다.
참고로, 삭제 대상 단어의 마지막 글자가 isLastChar false이거나 해당하는 마지막 글자가 없는 경우는 new Error를 던지도록 구현했습니다.