
[ETC] About AI
AI가 발전하면서 우리의 일상 곳곳에 스며들어있다. 그래서 간략하게 AI에 대해서 알아보려고 글을 작성하게 되었다.
인공지능이라는 개념은 1956년 미국 다트머스 대학에 있던 존 매카시 교수가 개최한 다트머스 회의에서 처음 등장했으며, 최근 몇년 사이 폭발적으로 성장하고 있는 중이다. 특히, 2015년 이후 신속하고 강력한 병렬 처리 성능을 제공하는 GPU의 도입으로 더욱 가속화되고 있기도 하다. 갈수록 폭발적으로 늘어나고 있는 저장 용량과 이미지, 텍스트, 매핑 데이터 등 모든 영역의 데이터가 범람하게 된 ‘빅데이터’ 시대의 도래도 이러한 성장세에 큰 영향을 미쳤다.
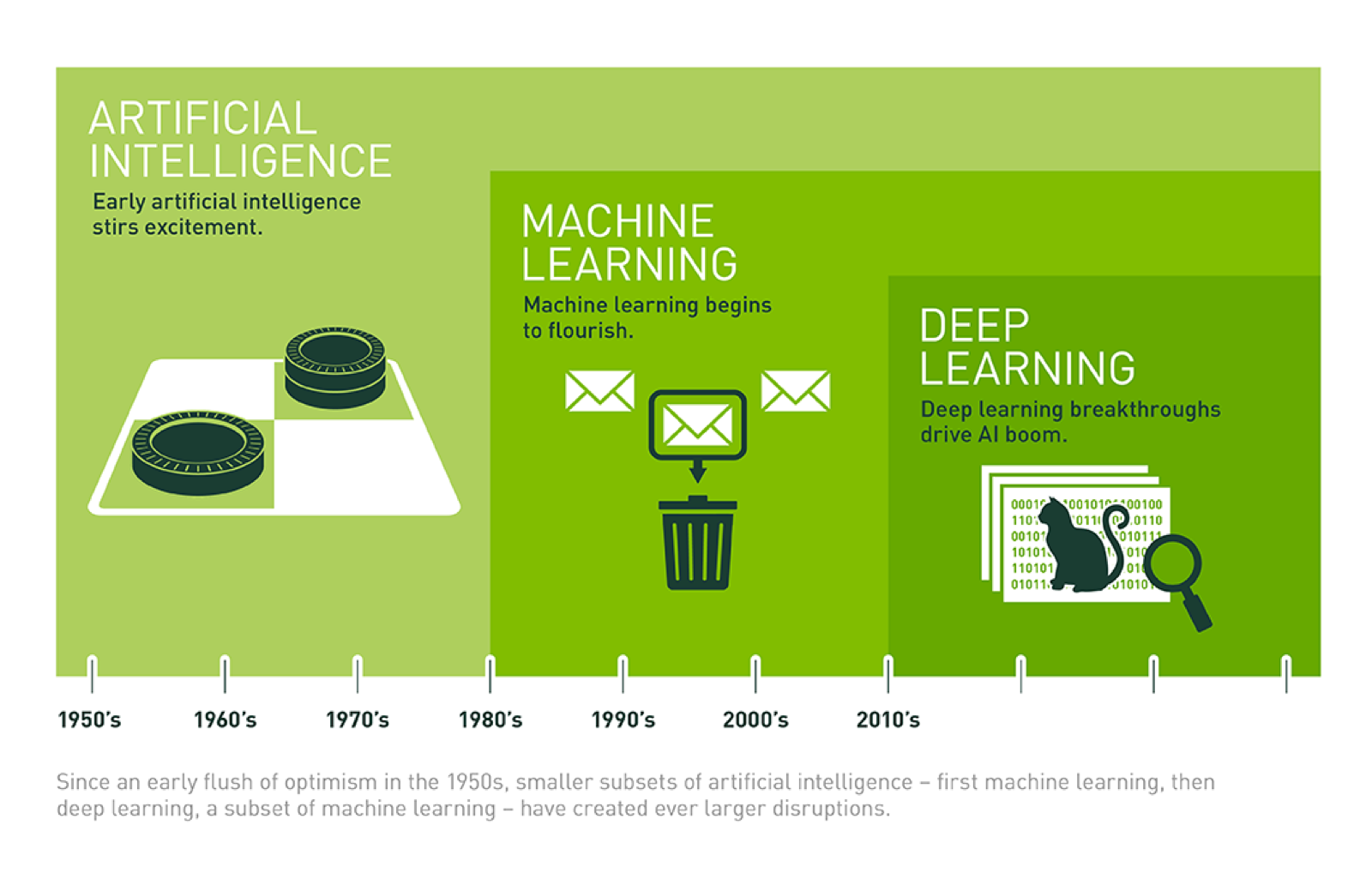
위의 그림이 인공지능에 대해 잘 표현해준다. 가장 큰 범주에 AI 인공지능이 있고 그 안에 머신러닝 그 안에 딥러닝이 존재한다.
인공지능이란?
기계를 지능적으로 만드는 과학이다. 기계는 문제를 해결할 때, 알고리즘을 기반으로 문제를 해결하게 되는데 AI 알고리즘은 규칙이 생성되는 방식에서 기존 알고리즘과 차이가 존재한다.
기존의 알고리즘에서 개발자는 소프트웨어가 수신하는 각 유형의 입력값들에 대한 출력을 정의하는 특정 규칙을 설정하는 반면에 AI 알고리즘은 자체 규칙 시스템을 구축하게 된다. 이는 AI를 통해 컴퓨터가 사람에게 전적으로 의존했던 작업을 스스로 해결할 수 있음을 의미한다.
머신 러닝이란?
인공지능의 하위 집합 개념인 머신 러닝은 정확한 결정을 내리기 위해 제공된 데이터를 통하여 스스로 학습할 수 있다. 처리될 정보에 대해 더 많이 배울 수 있도록 많은 양의 데이터를 제공해야 한다.
즉, 빅데이터를 통한 학습 방법으로 머신러닝을 이용할 수 있다. 머신 러닝은 기본적으로 알고리즘을 이용해 데이터를 분석하고, 분석을 통해 학습하며 학습한 내용을 기반으로 판단이나 예측을 한다. 따라서 궁극적으로는 의사결정 기준에 대한 구체적인 지침을 소프트웨어에 직접 코딩해 넣는 것이 아닌, 대량의 데이터와 알고리즘을 통해 컴퓨터 그 자체를 '학습’시켜 작업 수행 방법을 익히는 것을 목표로 한다.
딥러닝이란?
인공신경망에서 발전한 형태의 인공지능으로, 뇌의 뉴런과 유사한 정보 입출력 계층을 활용해 데이터를 학습한다. 그러나 기본적인 신경망조차 굉장한 양의 연산을 필요로 하는 탓에 딥러닝의 상용화는 초기부터 난관에 부딪혔다.
그럼에도 제프리 힌튼(Geoffrey Hinton) 교수 연구팀과 같은 일부 기관에서는 연구를 지속했고, 슈퍼 컴퓨터를 기반으로 딥러닝 개념을 증명하는 알고리즘을 병렬화하는 데 성공했다. 그리고 병렬 연산에 최적화된 GPU의 등장은 신경망의 연산 속도를 획기적으로 가속하며 진정한 딥러닝 기반 인공지능의 등장을 불러왔다.
딥러닝으로 훈련된 시스템의 이미지 인식 능력은 이미 인간을 앞서고 있다. 이 밖에도 딥러닝의 영역에는 혈액의 암세포, MRI 스캔에서의 종양 식별 능력 등이 포함된다. 구글의 알파고는 바둑의 기초를 배우고 자신과 같은 AI를 상대로 반복적으로 대국을 벌이는 과정에서 그 신경망을 더욱 강화해 나갔다.
머신러닝과 딥러닝의 차이점
머신러닝과 딥러닝의 가장 큰 차이점은 다음과 같다.
- 딥러닝은 분류에 사용할 데이터를 스스로 학습할 수 있다.
- 머신러닝은 학습 데이터를 수동으로 제공해야 한다는 점이다.