[Data Structure] Array vs LinkedList
2019.03.20 일자 기준으로 공부했던 내용을 수정하려고 한다. 이유는 이렇게 정리해놨지만 머리에 기억으로 남지 않기 때문이다.
먼저, Array VS LinkedList를 비교해보겠다.
Array(배열)
- 논리적 저장순서와 물리적 저장 순서가 일치한다.
인덱스로 해당 원소에 접근이 가능하다.- 인덱스만 알고 있다면 시간 복잡도 O(1)만에 해당 원소로 접근할 수 있다.
- 즉, Random Access가 가능하다.
- 배열의 원소를 삭제할 경우 삭제한 원소보다 큰 인덱스를 가진 원소들을 옮겨줘야(Shift) 하기 때문에 시간 복잡도 O(n)이 걸린다.
- 삽입의 경우, 새로운 원소를 추가하고 모든 원소들의 인덱스를 1씩 Shift 해줘야 하므로 시간 복잡도 O(n)이 걸린다.
- 제한적인 크기를 갖는다.
즉, 삭제 또는 삽입 과정에서 해당 원소에 접근하여 작업을 완료한 뒤 Shift를 해줘야 하는 cost가 발생해 O(n)의 시간복잡도를 갖는다.
LinkedList
- 자료의 주소 값으로 노드를 이용해 서로 연결되어 있는 구조를 갖는다.
- 삽입과 삭제의 경우 LinkedList가 Array보다 속도가 빠르다고 하지만 엄밀히 말하면 경우에 따라 다르다고 하는게 맞다. (아래에서 설명하겠다.)
- 원하는 값을 찾기 위해서 최소 한 번은 리스트를 순회하여야 하므로 O(n)의 시간 복잡도를 갖는다.
- 트리의 근간이 되는 자료구조이다.
LinkedList 역시 삽입과 삭제를 위해서 해당 노드를 찾아가는 동안 O(n)의 시간 복잡도를 갖는다. 추가적으로 데이터를 삽입 / 삭제하기 위한 시간 복잡도까지 계산하면 결국 O(n)의 시간 복잡도를 갖는 셈이다.
하지만 위에서 경우에 따라서 다르다고 하지 않았는가?
삽입의 경우
일단, LinkedList는 어느 곳에 삽입하던지 O(n)의 시간복잡도를 갖는다. (만약, 중간 삽입이 없다면 즉 맨 앞과 맨 뒤에만 삽입한다면 -> 시간 복잡도 : O(1))
삭제의 경우
삭제의 경우도 삽입과 마찬가지이다. 어느 곳에 삽입하던지 O(n)의 시간 복잡도를 갖는다. (만약, 중간 삭제가 없고 맨 앞과 뒤에서만 삭제한다면 -> 시간 복잡도 : O(1))
Array VS LinkedList
# 데이터 접근 속도
Array는 인덱스를 사용해 빠르게 원소에 접근할 수 있다. 따라서 Random Access를 지원한다. 시간 복잡도 O(1)로 빠르게 찾을 수 있다.
LinkedList는 순차 접근 방식을 사용한다. 특정 원소에 접근하기 위해서는 처음부터 원소에 도달할 때까지 순차적으로 검색하면서 찾는다. 시간 복잡도 O(N)
# 데이터의 삽입 속도
경우에 따라 다르다.
만약 배열에 공간이 많이 남아있고 맨 끝에 삽입한다면 삽입 속도 역시 O(1)에 가능하다. 하지만 이런 경우는 발생하기 힘든 케이스이다.
Array(배열)의 경우 데이터를 중간이나 맨 앞에 삽입할 경우 그 이후의 데이터를 한 칸씩 미뤄야 하는 추가 과정과 시간이 소요된다. 데이터가 많을 경우 비효율적이다. 그렇기 때문에 LinkedList가 필요하게 되었다.
LinkedList는 어느 곳에 삽입하던지 O(N)의 시간 복잡도를 갖는다.(만약, 중간 삽입이 없다면 O(1)의 시간복잡도를 갖는다.) 이유는 삽입할 위치를 찾고(O(N)) 삽입 연산을 진행하기 때문에 O(N)의 시간 복잡도를 갖는다. 그럼에도 Array보다 빠른 성능을 보인다.
또한 Array의 경우 데이터 삽입 시 모든 공간이 다 차버렸다면 새로운 메모리 공간을 할당받지만 LinkedList는 그럴 필요가 없다. 추가할 때마다 동적으로 할당하는 것으로 알고 있다.
# 데이터의 삭제 속도
이 부분도 경우에 따라 다르다.
Array는 데이터 삭제의 경우 그 위치의 데이터를 삭제 후, 전체적으로 Shift 해줘야 한다. (O(N))
LinkedList의 경우 삭제할 원소를 찾기 위해서 O(N)의 시간 복잡도를 갖고 삭제를 한다. 결구 O(N)의 시간 복잡도를 갖는다. 하지만 Array 보다 빠르게 삭제 연산을 수행한다.
# 메모리 할당
-
Array에서 메모리는 Array가 선언되자 마자 Compile time에 할당되어 진다. 이것을 정적 메모리 할당이라고 한다. -
Stack 영역에 메모리 할당이 이루어진다.
-
LinkedList에서 메모리는 새로운 node가 추가될 때 runtime에 할당되어 진다. 이것은 동적 메모리 할당이라고 한다. -
Heap 영역에 메모리 할당이 이루어진다.
# size
Array의 size는 반드시 선언 시점에 지정되어있어야 한다.
LinkedList의 size는 다양할 수 있다. node들이 추가될 때 runtime 시점에서 LinkedList의 size가 커질 수 있기 때문이다.
결론
- 삽입과 삭제가 빈번하다면 LinkedList를 사용하는 것이 더 좋다.
- 데이터의 접근하는 게 중요하다면 Array를 사용하는 것이 좋다.
전반적인 내용을 보면 Array보다 LinkedList(포괄적인 범위에서 List라고 하겠다.)의 사용이 훨씬 좋아보인다. 하지만 일반적인 알고리즘 문제를 풀 때는 List보다 Array가 훨씬 빠르고 좋다. 왜냐하면 대부분의 알고리즘 문제는 메모리 공간의 범위를 파악할 수 있도록 N의 크기가 주어지기 때문이다.
그래서 배열의 크기를 MAX로 초반에 잡을 수 있다면 훨씬 더 편리하고 List와는 다른 속도를 보인다. 왜냐하면 위에서 본 것처럼 List의 입력마다 메모리의 할당이 일어나고 삭제에서는 메모리 해제가 일어난다. 이런 작업은 시간복잡도에 포함되지는 않지만 시스템 콜(System Call)을 사용하는 구문은 시간 소요가 꽤 걸린다.
사용하려는 목적에 따라서 Array와 List를 구분해서 사용하면 된다.
자자, 위에서는 Array와 LinkedList의 차이점을 살펴보았다. 이번에는 ArrayList와 LinkedList의 차이를 살펴보겠다. 사실 위에서 본 것과 차이는 거의 없다고 생각한다. 이유는 ArrayList가 단지 내부적으로 Array(배열)를 사용하고 List 인터페이스를 구현했기 때문에 거의 똑같다고 생각한다. 그래도 한 번 살펴보자.
ArrayList vs LinkedList
1. ArrayList
- 내부적으로 데이터를 배열에서 관리하며 데이터의 추가, 삭제를 위해서 임시 배열을 생성해 데이터를 복사하는 방법을 사용한다.
- 대량의 자료를 추가/삭제 하는 경우 그만큼 데이터의 복사가 많이 일어나게 되어 성능 저하가 발생
- 중간에 데이터를 삽입하기 위해서는 연속된 빈 공간이 존재해야 한다.
- 반면 인덱스를 가지고 있어서 한 번에 참조가 가능해 데이터 검색에 유리하다.
ArrayList는 삽입과 삭제를 할 일이 없거나 배열의 끝에서만 하게 될 경우 유용하게 쓰일 수 있다. 원소에 대해 빠르게 접근할 수 있을 뿐만 아니라, 원소들이 메모리에 연속으로 배치해 있어 CPU 캐시 효율도 더욱 높다.
2.LinkedList
- 데이터를 저장하는 각 노드가 이전 노드와 다음 노드의 상태만 알고 있으면 된다.
- ArrayList와 달리 데이터의 추가, 삭제시 불필요한 데이터의 복사가 없어 데이터의 추가, 삭제시에 유리하다.
- 반면, 데이터 검색 시에는 처음부터 노드를 순회하기 때문에 성능상 불리하다.
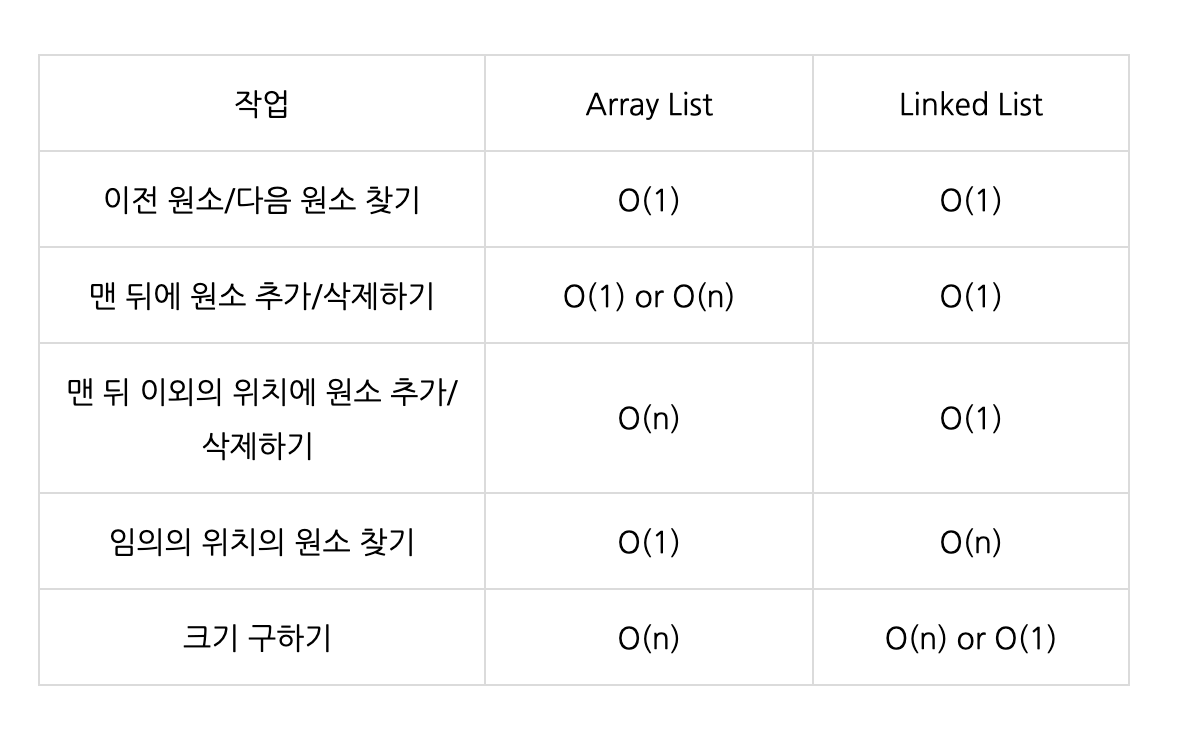
3. 데이터의 검색,삽입,삭제시 성능 비교
검색
- ArrayList : 인덱스 기반이기 때문에 O(1)의 시간복잡도를 갖는다.
- LinkedList : 검색 시 모든 요소를 순차적으로 탐색해야 하기 때문에 O(N)의 시간 복잡도를 갖는다.
삽입,삭제
- ArrayList : 삽입,삭제 이후 다른 데이터를 복사해야 하기 때문에 O(N)의 시간복잡도를 갖는다.
- LinkedList : 이전 노드와 다음 노드를 참조하는 상태만 변경하면 되기 때문에 삽입, 삭제 시에 O(1)의 시간 복잡도를 갖는다. 하지만 이 부분도 경우에 따라 다르다.