[네트워크] 흐름/혼잡/오류 제어 기법
TCP의 가장 큰 특징은 신뢰성이다. 이러한 신뢰성을 구성해 주는 방법인 흐름 제어, 혼잡 제어, 오류 제어에 대해 알아보도록 하자.
흐름 제어
송신(호스트) <> 수신(호스트)
흐름 제어는 수신측과 송신측의 데이터 처리 속도 차이를 해결하기 위한 기법이다.
만약 송신측의 전송량이 수신측의 처리량보다 많은 경우, 전송된 패킷은 수신측의 큐를 넘어서 손실될 문제가 발생할 수 있기 때문에 송신측의 패킷 전송량을 제어하게 된다.
흐름 제어 방법
- 정지-대기(Stop and Wait)
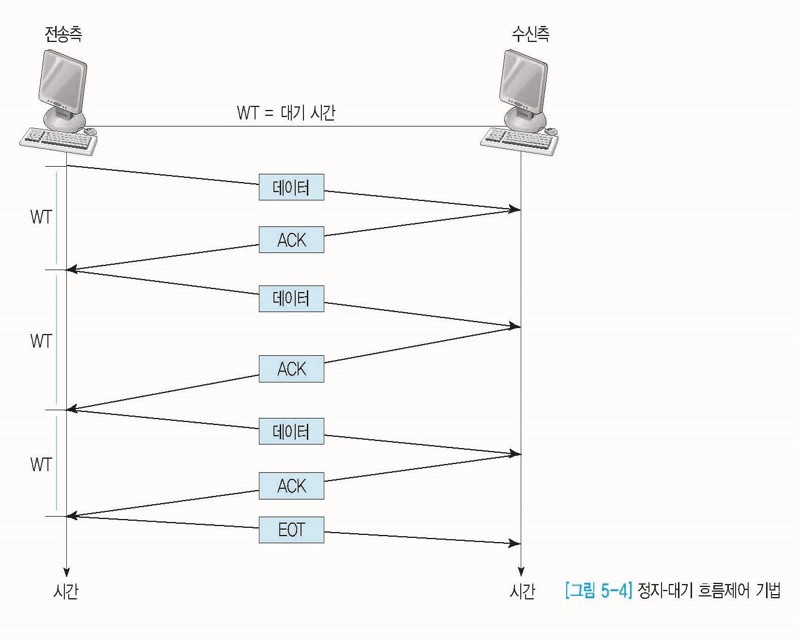
- 매번 전송한 패킷에 대해 응답을 받아야만 그 다음 패킷을 전송할 수 있다.
- 구조가 간단한 대신, 하나를 주고 하나를 받기 때문에 비효율적이다.
- 슬라이딩 윈도우(Sliding Window)
수신측에서 설정한 윈도우 크기만큼 송신측에서 확인 응답 없이 세그먼트를 전송할 수 있게 하여 데이터 흐름을 동적으로 조절하는 기법이다.
이처럼 슬라이딩 윈도우 기법을 통하여 송신 버퍼의 범위는 수신 측의 여유 버퍼 공간을 반영하여 동적으로 바뀜으로써 흐름제어를 수행한다.
- 윈도우는 전송, 수신 스테이션 양쪽에서 만들어진
버퍼(Buffer)의 크기이다. - 윈도우의 크기 = (가장 최근 ACK로 응답한 프레임의 수) - (이전에 ACK 프레임을 보낸 프레임의 수)
- 슬라이딩 윈도우 기법은 Stop and Wait 기법의 비효율성을 개선한 기법이다.
- ACK 프레임을 수신하지 않더라도 여러 개의 프레임을 연속적으로 전송할 수 있다.
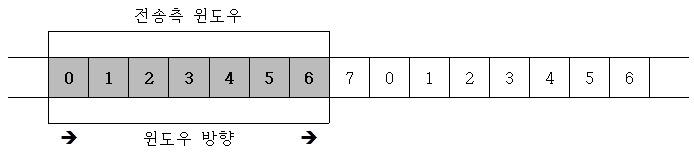
위와 같은 구조에서 데이터 0과 1을 전송했다고 가정하면 슬라이딩 윈도우의 구조는 아래와 같이 변한다. 윈도우의 크기는 전송한 데이터 프레임만큼 왼쪽 경계가 줄어들게 된다.
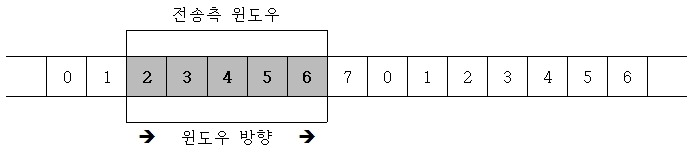
이때 수신측에서 ACK라는 프레임을 받게 된다면 전송측은 0과 1 데이터를 정상적으로 받았음을 알게 되고, 전송측은 ACK 프레임에 따른 프레임의 수만큼 오른쪽으로 경계가 확장된다.
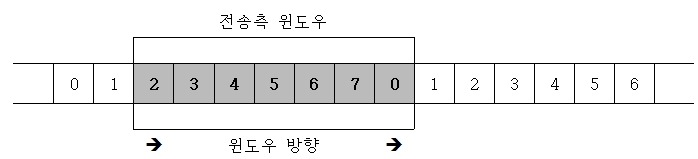
조금 더 자세한 설명
# 전송측 윈도우
# 수신측 윈도우
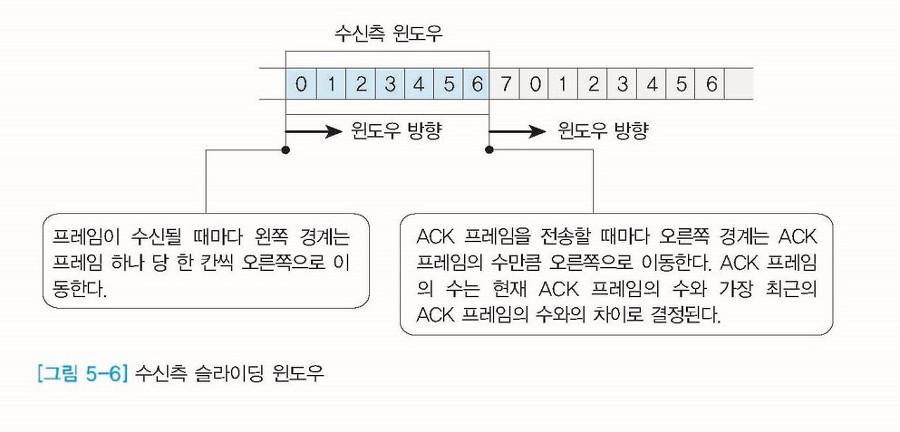
혼잡 제어
송신(호스트) <> 라우터(네트워크)
혼잡 제어는 송신측의 데이터 전달과 네트워크의 데이터처리 속도 차이를 해결하기 위한 기법이다.
송신측의 데이터는 지역망이나 인터넷으로 연결된 대형 네트워크를 통해 전달된다. 하지만 이러한 네트워크 상의 라우터가 항상 한가로운 상황은 아니다. 만약, 한 라우터에게 데이터가 몰릴 경우 다시 말해 혼잡할 경우, 라우터는 자신에게 온 데이터를 모두 처리할 수 없다.
그렇게 되면 호스트들은 또 다시 재전송을 하게 되고 결국 혼잡을 가중시켜 오버플로우나 데이터 손실을 발생시킨다. 따라서, 이러한 네트워크의 혼잡을 피하기 위해 송신측에서는 보내는 데이터의 전송 속도를 강제로 줄이게 된다.
혼잡 제어 방법
- AIMD
AIMD(Additive Increase / Multiplicative Decrease)라고 불리며, 합 증가 / 곱 감소라고 부른다.
처음에 패킷을 하나씩 보내고 이것이 문제없이 도착하면 window 크기(단위 시간내에 보내는 패킷의 수)를 1씩 증가시켜 가면서 전송하는 방법이다. 만일 패킷 전송을 실패하거나 일정한 시간을 넘으면 패킷 전송 속도를 절반으로 줄이게 된다.
이 방식은 공평한 방식이다. 이 방식을 사용하는 여러 호스트가 한 네트워크를 공유하고 있으면 나중에 진입하는 쪽이 처음에는 불리하지만 시간이 흐르면 평형 상태로 수렴하게 되는 특징이 있다.
문제점은 초기에 네트워크의 높은 대역폭을 사용하지 못하며 오랜 시간이 걸리게 되고 네트워크가 혼잡해지는 상황을 미리 감지하지는 못한다. 즉, 네트워크가 혼잡해지고 나서야 대역폭을 줄이는 방식이다.
이러한 문제점들을 해결하기 위한 방법은 다음부터 소개될 것이다.
- 슬로우 스타트(Slow Start)
AIMD 방식은 네트워크의 수용량 주변에서는 효율적으로 작동하지만 처음에 전송 속도를 올리는 데 걸리는 시간이 너무 길다는 단점이 있다.
Slow Start 방식은 AIMD 방식과 마찬가지로 패킷을 하나씩 보내는 것부터 시작하고 이 방식은 패킷이 문제없이 도착하면 각각의 ACK 패킷마다 Window Size를 1씩 늘린다. 즉, 한 주기가 지나면 Window size가 2배가 된다.
따라서 전송 속도는 AIMD와는 다르게 지수 함수꼴로 증가하게 된다. 대신 혼잡 현상이 발생하면 Window Size를 1로 떨어뜨리게 된다.
처음에는 네트워크의 수용량을 예상할 수 있는 정보가 없지만 한번 혼잡 현상이 발생하고 나면 네트워크의 수용량을 어느 정도 예상할 수 있으므로 혼잡 현상이 발생하였던 Window Size의 절반까지는 이전처럼 지수 함수 꼴로 Window Size를 증가시키고 그 이후부터는 완만하게 1씩 증가시키는 방식이다.
- 초기 혼잡 Window Size 1로 전송 = 전송 호스트는 하나의 패킷만 전송
- 수신 호스트로부터 수신응답을 수신하면 윈도우의 크기를 2로 하여 전송
- 수신 호스트로부터 수신응답을 수신하면 윈도우의 크기를 4로 하여 전송
- 수신 호스트로부터 수신응답을 수신하면 윈도위의 크기를 8로 하여 전송
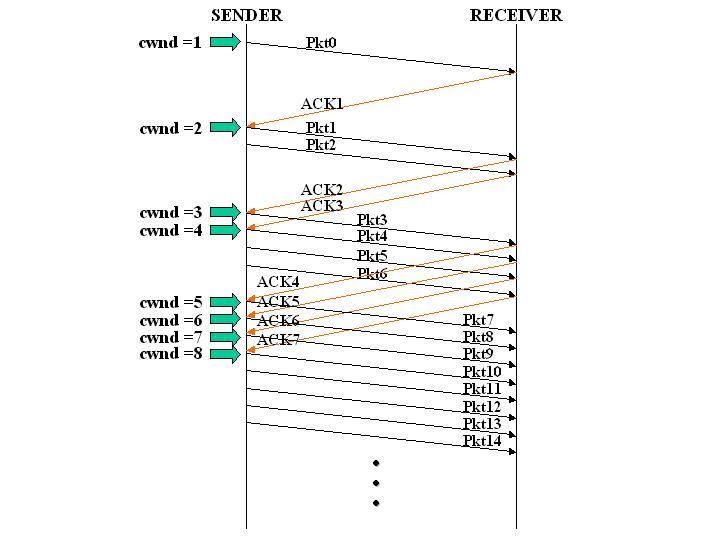
- 미리 정해진 임계 값(threshold)에 도달할 때까지 윈도우의 크기를 2배씩 증가시킨다.
- Slow Start란 이름을 사용하지만, 매 전송마다 두 배씩 증가하기 때문에 전송되어지는 데이터의 크기는 지수 함수적으로 증가한다.
- 전송되어지는 데이터의 크기가 임계 값에 도달하면 혼잡 회피 단계로 넘어간다.
- 혼잡 회피(Congestion Avoidance)
윈도우의 크기가 임계 값에 도달한 이후에 데이터의 손실이 발생할 확률이 높아지게 된다. 이는 데이터를 전송함에 있어서 조심하는 단계이다.
전송한 데이터에 대한 ACK를 받으면 윈도우의 크기를 1씩 증가시킨다.
전송하는 데이터의 증가를 왕복시간 동안에 하나씩만 증가시킨다.
- 수신 호스트로부터 일정 시간 동안까지 ACK를 수신하지 못하는 경우
- 타임아웃의 발생
- 네트워크에 혼잡이 발생했다고 인식
-> 윈도우의 크기를 즉, 세그먼트의 수를 1로 줄임
-> 동시에 임계 값을 패킷 손실이 발생하였을 때의 윈도우 크기의 반으로 줄임
- 빠른 회복(Fast Recovery)
빠른 회복은 Congestion이 발생했을 때 Window size를 1로 줄이지 않고 반으로 줄이고 선형 증가시키는 방법이다. 이는 AIMD의 AI 즉, Additive Increase 하는 방법이다.
Fast Recovery를 적용하면 혼잡 상황을 한 번 겪고 나서부터는 순수한 AIMD 방식으로 동작하게 된다.
- 빠른 재전송(Fast Retransmission)
3개의 연속된 중복 ACK를 수신하는 경우에 패킷의 손실로 간주하여 타임아웃이 발생하기 전에 해당 패킷을 재전송한다. 그리고 이러한 현상이 일어난 것은 약간의 혼잡이 발생한 것으로 간주하여 Window Size를 반으로 줄인다.
- TCP Reno
N개의 중복 ACK 발생 시 ssthresh(slow start threshold)값을 Congestion Window(cwnd) 사이즈의 반으로 줄여 빠른 복구(Fast Recovery)를 수행하여 선형적 증가를 하게 되며, TCP Time Out에 이르면 Slow Start를 시작한다.
- TCP Tahoe
N개의 중복 ACK 발생 시 바로 Slow Start를 시작한다.
TCP Tahoe와 TCP Reno는 ssthresh(slow start threshold) 값까지 지수적 증가(Slow-Start)를 하게 되고 ssthresh를 넘어서면 선형적 증가(Additive Increase)를 하는 것까지는 동일하다. 차이가 생기는 기준은 N개의 중복 ACK가 발생할 경우이다.
오류 제어
오류 제어 기법은 오류 검출(Error detection)과 재전송(retransmission)을 포함한다.
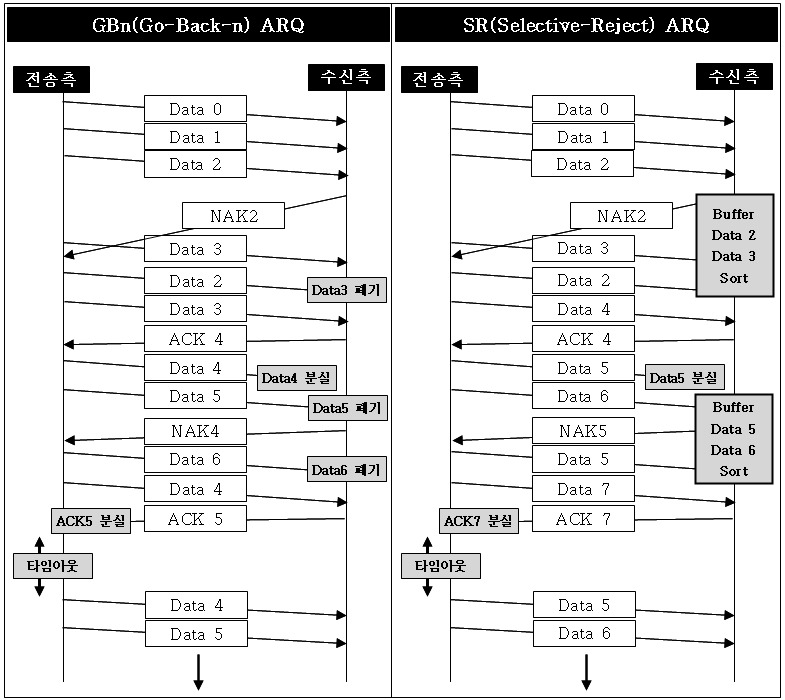
ARQ(Automatic Repeat Request) 기법을 사용하여 프레임이 손상되었거나 손실되었을 경우 재전송을 통해 오류를 복구한다. ARQ 기법은 흐름 제어 기법과 관련되어 있는데 stop and wait은 stop and wait ARQ로, Sliding Window는 GBn(Go-Back-n) ARQ 또는 SR(Selective-Reject) ARQ 형태로 구혀한다.
오류 제어 방법
ARQ : 신뢰성 있는 데이터 전달을 위해 재전송을 기반으로 한 에러 제어 방식
- Stop and Wait ARQ
전송측은 수신측에서 보내준 ACK를 받을 때까지 프레임의 복사본을 유지한다.
식별을 위해 데이터 프레임과 ACK 프레임은 각각 0,1 번호를 부여한다.
수신측이 데이터를 받지 못했을 경우, NAK를 송신측에게 보내고
NAK를 받은 송신측은 데이터를 재전송한다.
만약 데이터나 ACK가 분실되었을 경우 일정 간격의 시간을 두고 타임아웃이 되면 송신측은 데이터를 재전송한다.
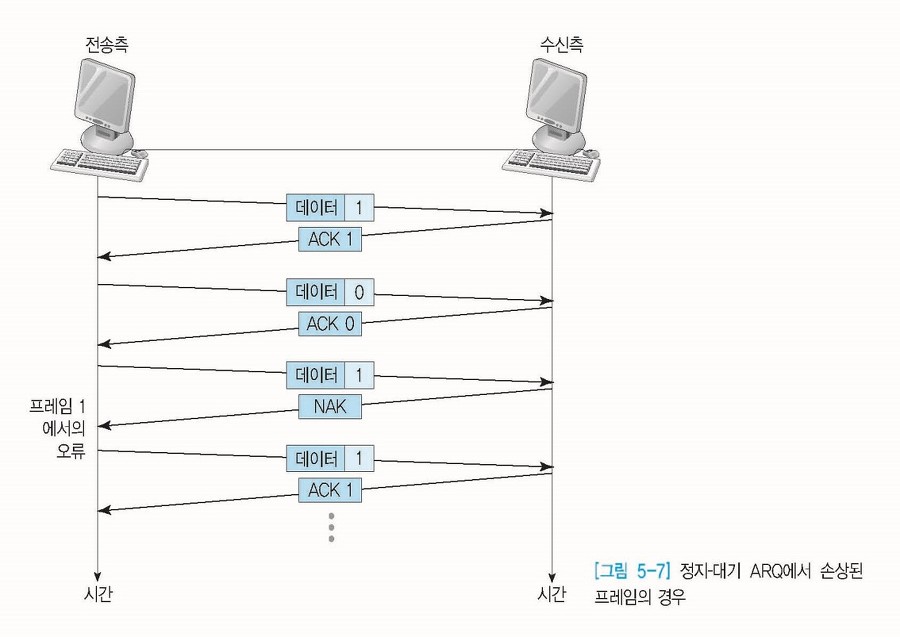
- Go-Back-n ARQ(GBn ARQ)
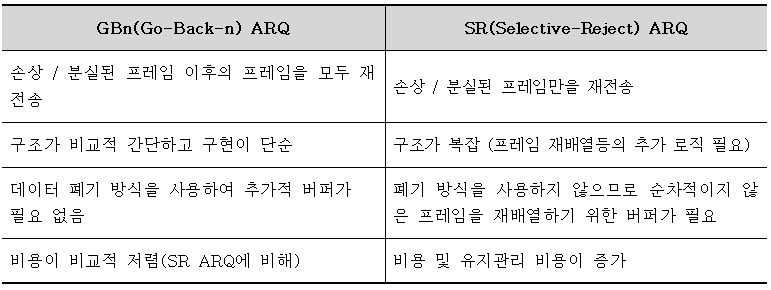
전송된 프렘이이 손상되거나 분실될 경우, 확인된 마지막 프레임 이후로 모두 재전송하는 기법이다.
슬라이딩 윈도우는 연속적인 프레임 전송 기법으로 전송 스테이션은 전송된 모든 프레임의 복사본을 가지고 있어야 하며, ACK와 NAK 모두 각각 구별을 해야한다.
- ACK : 다음 프레임을 전송
- NAK : 손상된 프레임 자체 번호를 반환
재전송 되는 경우는 다음과 같다.
# 1. NAK 프레임을 받았을 경우
만약 수신측으로 0부터 5까지의 데이터를 보내었다고 가정한다. 수신측에서 데이터를 받았음을 확인하는 ACK 프레임을 중간 중간 받게 되며, ACK 프레임을 확인한 전송측은 계속해서 데이터를 전송한다.
그러나 만약 수신측에서 데이터 오류 프레임2가 잘못 되었다는 것을 발견하고 NAK 2를 전송측에 보낸다. NAK 2를 받은 전송측은 데이터 프레임2가 잘못 되었다는 것을 알고 데이터를 재전송한다.
GBn ARQ의 특징은 바로 이 데이터를 재전송하는 부분이다. GBn ARQ는 NAK(n)을 받아 데이터를 재전송하게 되면, n 데이터만을 재전송하는 것이 아니라 n 데이터 이후의 데이터를 모두 재전송한다.
# 2. 전송 데이터 프레임의 분실
GBn ARQ의 특징은 확인된 데이터 이후의 모든 데이터 재전송과 수신측의 폐기이다. 수신측에서 데이터 1을 받았는데 갑자기 다음에 데이터 3을 받게 된다면 수신측에서는 데이터 2를 못받았으므로 데이터 3을 폐기하고 NAK 2를 전송측에 보낸다.
NAK 2를 받은 전송측은 위의 1의 경우에서와 같이 NAK 2 데이터부터 모두 재전송을 실시하며 수신측은 기존 받았던 데이터 중 NAK(n)으로 보내었던 대상 데이터 이후의 데이터를 모두 폐기하고 재전송 받는다.
# 3. 지정된 타임아웃 내의 ACK 프레임 분실(Lost ACK)
전송 스테이션은 분실된 ACK를 다루기 위해 타이머를 가지고 있다. 전송측에서는 이 타이머의 타임 아웃동안 ACK 데이터를 받지 못했을 경우, 마지막 ACK부터 재전송한다.
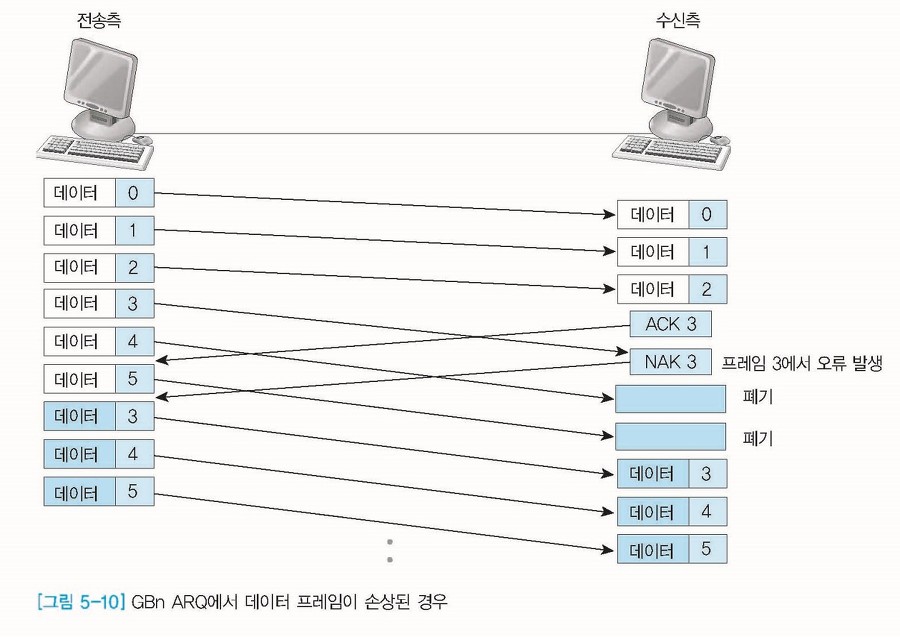
위의 그림은 송신측이 데이터 3을 보내고 수신측은 데이터 3을 받았지만 오류가 발생했을 경우이다. 이 경우에 송신측은 연속적으로 데이터를 보내지만 수신측은 데이터 3에서 오류가 발생했으므로 NAK 3을 송신측으로 보낸다.
수신측은 데이터 3 이후로 온 데이터 프레임을 모두 폐기하며 송신측은 데이터 3부터 재전송하게 된다.
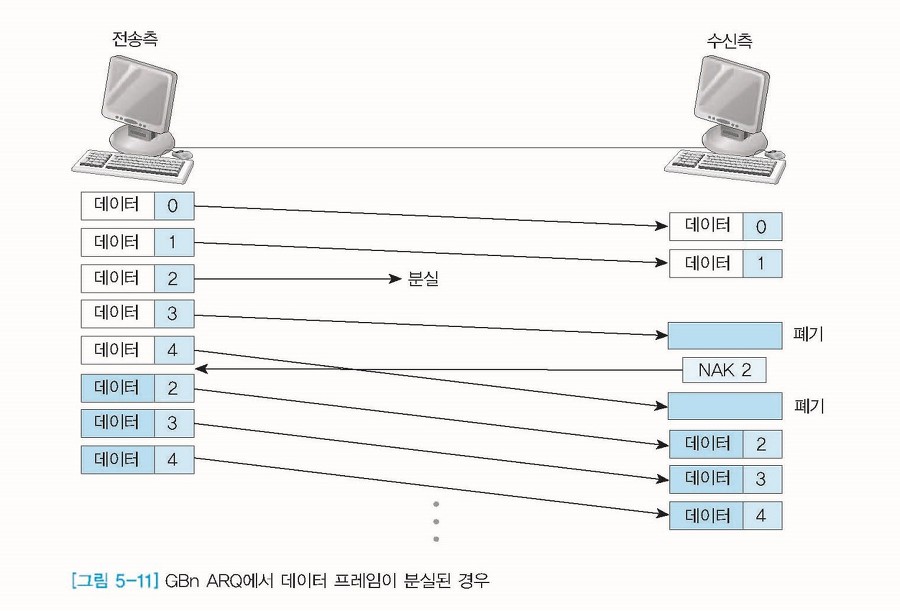
위의 그림은 송신측에서 데이터 2를 보내는 도중에 분실된 경우이다. 이 경우 수신측은 데이터 0, 1은 맞게 받았지만 2를 받지 않고 3을 받게 되어 받은 데이터를 폐기하고 NAK 2를 송신측에게 보낸다.
그럼 송신측은 NAK 2를 받고 데이터 2부터 송신측은 수신측으로 데이터를 재전송하게 된다.
- 전송측은 NAK 프레임을 받았을 경우, NAK 프레임 번호부터 다시 재전송한다.
- 수신측은 원하는 프레임이 아닐 경우 모두 폐기 처리한다.
- 타임아웃(ACK 분실)일 경우, 마지막 ACK된 데이터부터 재전송한다.
- Selective-Reject(SR) ARQ
GBn ARQ의 재전송되는 프레임 이후의 모든 프레임을 재전송하는 단점을 개선한 방법이다. SR ARQ는 손상된, 분실된 프레임만 재전송한다.
그렇기 때문에 별도의 데이터 재정렬을 수행해야 하며, 별도의 버퍼를 필요로 한다.
GBn ARQ 기법과 SR ARQ 기법의 비교